

1. Why SPL Still Matters (and Why SPL2 Exists)
Splunk Processing Language (SPL) is a stream-based, pipeline-oriented query language.
It processes events sequentially, command by command, transforming a flowing stream of events into progressively smaller or more structured result sets.
SPL2 does not replace SPL. It is about making intent and optimization explicit for large-scale analytics.
Mental model difference :
| Concern | SPL | SPL2 |
| Execution clarity | Implicit | Explicit |
| Optimization visibility | Low | Higher |
| Dataset safety | Mutable | Immutable |
| Learning curve | Lower | Higher |
2. SPL Execution Mental Model (Critical)
Before commands, understand execution.
SPL executes as :
- Event retrieval (from indexers)
- Search-time parsing
- Command-by-command transformation
- Final result materialization
Each command :
- Receives the entire output of the previous command
- May reduce cardinality (e.g., stats)
- May destroy event context permanently
3. search - The Root of All Queries
The 'search' command filters events as early as possible.

index=_internal error- Retrieve events from _internal
- Filter events containing the term error
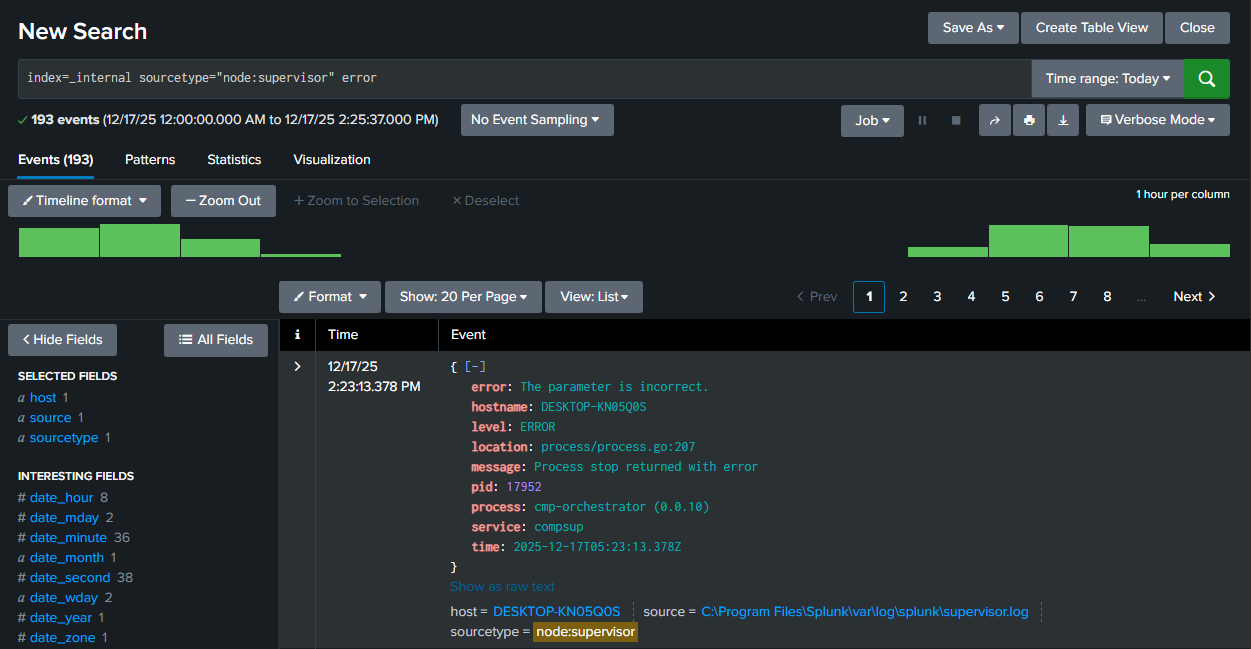
index=_internal sourcetype=splunkd ERROR- Field-based filtering (sourcetype, component) is pushed down to Indexers
- Free-text terms are evaluated later
Performance Rule
Field filters first, keywords second.
- Bad :
index=_internal error sourcetype=splunkd- Good :
index=_internal sourcetype=splunkd errorSPL2 Perspective
In SPL2, filtering becomes an explicit dataset operation:

from index:_internal
| where sourcetype == "splunkd" and like(_raw, "%ERROR%")Key Difference from `search`
- search can leverage index-time metadata
- where cannot
- Use where only when:
- You rely on computed fields (eval)
- You require numeric comparisons
- Use where only when:
4. stats - The Most Important Command in SPL
The 'stats' transforms events into aggregated datasets.
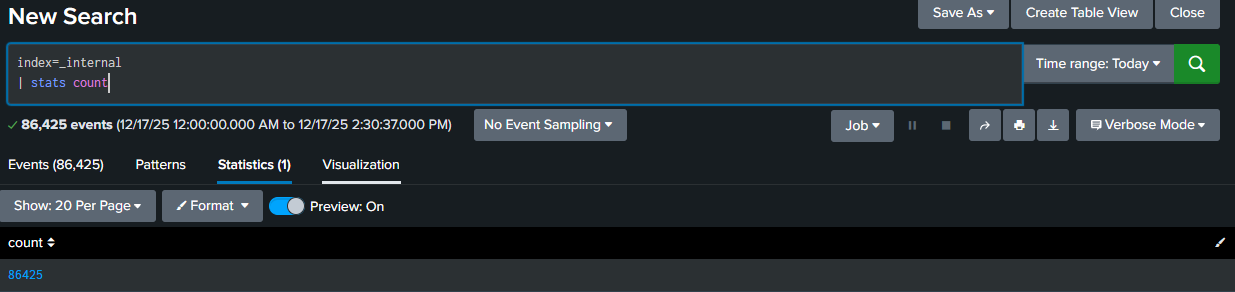
index=_internal
| stats count

index=_internal
| stats count avg(exec_time) max(exec_time) by component4. eval — Field Engineering Engine
The 'eval' creates or transforms fields.
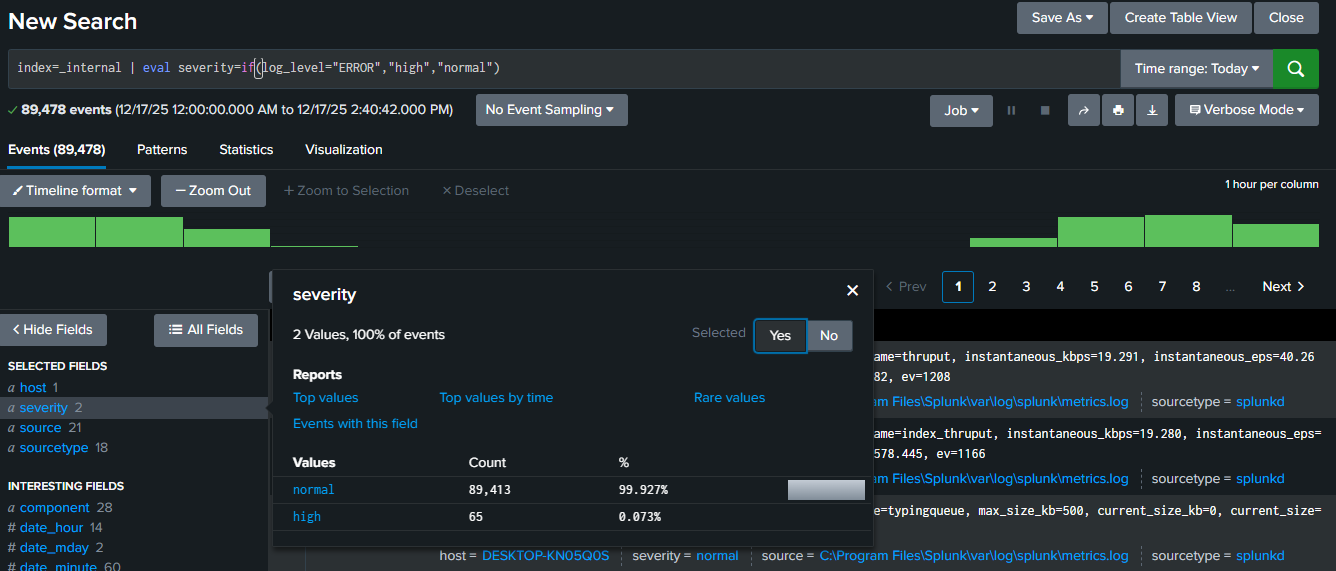
index=_internal | eval severity=if(log_level="ERROR","high","normal")
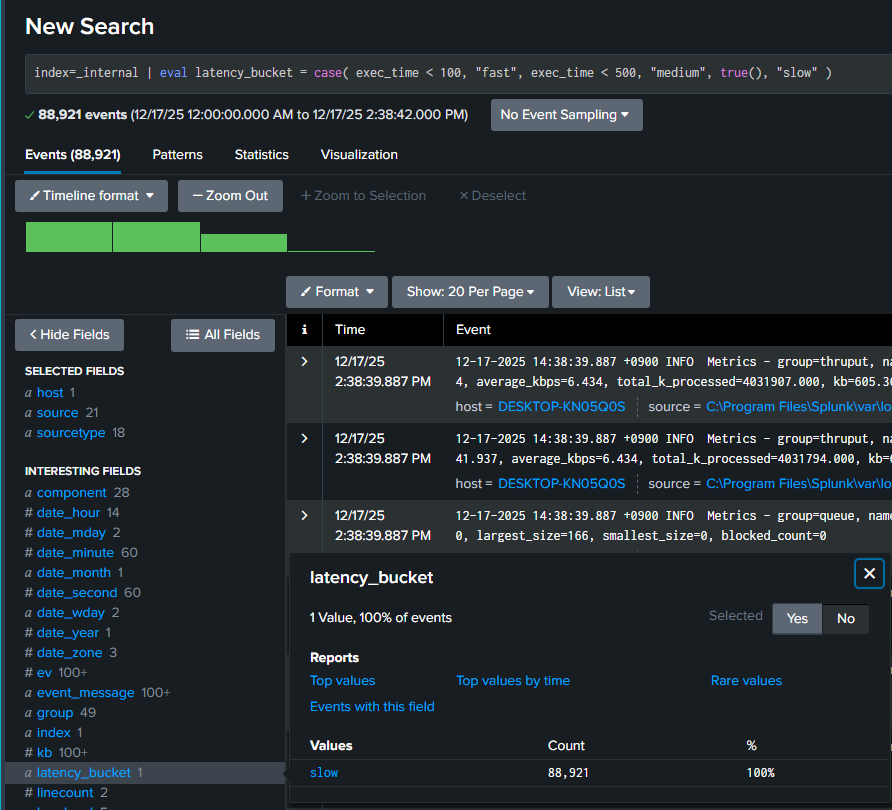
index=_internal
| eval latency_bucket = case(
exec_time < 100, "fast",
exec_time < 500, "medium",
true(), "slow"
)Performance Rule
- Cheap arithmetic is fine
- Avoid heavy string operations on large datasets
5. rex — Search-Time Extraction
The 'rex' keyword is Regex-based field extraction.

index=_internal
| rex field=_raw "component=(?<component>[^\s]+)"
| stats count by componentIndex-Time vs Search-Time Tradeoff
- Repeated rex on hot paths → must be moved to props.conf
- One-off investigations → acceptable
7. sort, limit, dedup — Result Shaping Commands
index=_internal
| sort -_time
| limit 10
The command 'dedupe' removes duplicate rows based on one or more field values, keeping only the first occurrence.
Performance Warning
sort is expensive. Always:
- Reduce data first
- Sort last
8. transaction — Powerful but Dangerous
The 'transaction' aggregates event correlation across time.
index=_internal | transaction host maxspan=5mWarning
- Memory-heavy
- Non-parallel
- Prefer stats or streamstats when possible
References
- Differences between SPL and SPL2 | Splunk Docs
- Splunk Cheat Sheet: Query, SPL, RegEx, &Commands | Splunk Docs
- Commands by category | Splunk Help
-
Powered By. ChatGPT
'Splunk' 카테고리의 다른 글
| [Multi-cloud] 멀티클라우드 보안 로그와 IAM 위임 구조 이해하기 - AWS, Azure, GCP를 아우르는 SIEM 설계 (0) | 2025.12.25 |
|---|---|
| [Splunk] Splunk Topologies (0) | 2025.12.05 |
| [Splunk] Splunk Architecture : From Log Ingestion to Scalable Security Analytics (0) | 2025.11.18 |