DNS over QUIC(DoQ)로 보는 Layered architecture와 프로토콜 설계 원칙
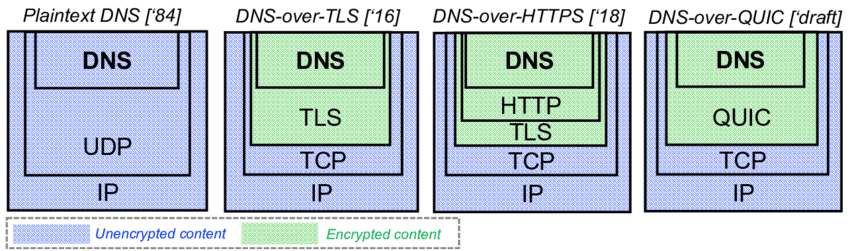
1. DoQ 스택으로 보는 현대 프로토콜의 계층화 구조
DNS over QUIC (DoS)는 전형적인 Layered Architecture 사례다.
개념적으로 보면 UDP ⊃ QUIC ⊃ TLS ⊃ HTTPS ⊃ DNS 구조를 통해, 각 계층은 자신의 역할만 수행하고 상위 계층의 데이터를 페이로드로 운반한다.
이 구조의 핵심은 역할 분리와 교체 가능성이다.
DNS는 전송 방식이나 암호화 방식이 바뀌어도 논리 자체는 유지된다.
현대 서버 환경에서 최소 3단 이상의 계층을 사용하는 이유는 보안, 확장성, 운영 유연성을 동시에 확보하기 위함이다.
게임은 예외적으로 1단 프로토콜을 사용하는데, 이 표현은 암호화나 보안을 생략한다는 의미가 아니다.
실제로는 지연(latency)와 오버헤드를 줄이기 위해 여러 계층을 하나의 커스텀 프로토콜로 통합하는 경우가 많다는 뜻이다.
즉, 논리적 계층은 존재하지만 구현상 단일 스택처럼 동작하도록 최적화한 사례로 이해하는 것이 정확하다.
2. 헤더 최소화와 확장성의 Trade-off
프로토콜 설계에서 자주 등장하는 원칙 중 하나는 "헤더는 작을수록 좋다"는 것이다.
헤더 필드가 많아질 수록 구현은 직관적이지만, 파싱 복잡도와 상호운용성 문제가 급격히 증가한다.
반대로 헤더를 최소화하면 초기 구현은 불편하지만 장기적으로는 확장과 진화에 유리한 구조를 만들 수 있다.
즉, 핵심 메타데이터만 헤더에 두고, 나머지는 확장 메커니즘으로 분리하는 것이 현대 프로토콜 구현의 대세 중 하나이다.
3. Body 중심 설계와 Encapsulation
Body(페이로드)는 무엇이든 담을 수 있는 공간이라는 점에서 계층화의 핵심이다.
하위 프로토콜은 Body의 내용을 해석하지 않고 그대로 전달하며, 상위 프로토콜만 의미를 부여한다.
이로 인해 하나의 프로토콜은 또 다른 프로토콜의 컨테이너가 될 수 있고, 계층은 재귀적으로 쌓인다.
DoQ 역시 QUIC 페이로드 위에 암호화된 DNS 메시지를 얹는 방식으로 이 원리를 그대로 활용한다.
4. 확장 메커니즘 : TLV와 Length·Type·Decoding 문제
프로토콜이 성장하면 length, type, decoding 같은 세부 정보를 담은 필드를 추가하고 싶을 수 있다.
하지만 무작정 헤더에 필드를 늘린다면 헤더는 비대해지고, 버전 충돌과 파편화(fragmentation)가 발생한다.
그래서 실무에서는 TLV(Type-Length-Value) 구조나 옵션 필드, 협상 기반 확장을 사용한다.
핵심은 "고정 헤더는 안정적으로, 기능 확장은 선택적으로" 원칙이다.
DoQ 사례는 현대 프로토콜 설계 방식 중 대표적인 하나를 명확히 보여준다.
헤더는 최소화하고, Body는 유연하게, 확장은 TLV와 Reserved로 흡수한다.
5. Reserved 필드 : "미래를 위한 프로토콜 설계"
RTSP, RIFF 같은 프로토콜이 Reserved 필드를 두는 이유는 명확하다.
지금 당장은 쓰지 않더라도, 미래 확장을 위한 공간을 미리 확보하는 것이다.
Reserved 필드는 프로토콜을 깨지 않고 기능을 추가할 수 있는 안전핀 역할을 한다.
다만 모든 구현체가 임의로 사용하지 않도록 "0으로 채우고 무시하라" 같은 규칙이 반드시 병행되어야 한다.
OutputStream.write() 성능 병목의 본질과 DMA 기반 I/O 최적화 전략
1. OutputStream.write()은 왜 느려질 수 있는가
OutputStream.write()은 단순히 메모리에 데이터를 복사하는 메서드가 아니다.
이 호출은 내부적으로 OS 커널을 통해 파일 기술자 또는 소켓에 데이터를 전달한다.
즉, write는 항상 user space → kernel space경계를 넘는 연산으로, 이 자체가 이미 고비용이다.
문제는 write이 작은 단위로, 빈번하게 호출될 때 발생한다.
2. write 호출의 실제 비용 : System call과 커널 경계
write이 호출되면 다음 흐름에 따라 실행된다.
- 애플리케이션이 system call을 통해 커널 진입
- 커널이 데이터 유효성 검사 및 버퍼 관리 수행
- I/O subsystem과 Driver 계층으로 전달
이 과정에서 발생하는 model switching, context 관리, 캐시 무효화는 CPU 연산보다 훨씬 비싸다.
따라서 성능 문제의 본질은 "I/O 속도"가 아니라 system call 경계 비용이다.
3. 작은 write 누적 문제와 I/O 집계 전략
작은 write을 여러 번 호출하는 구조는 다음 문제를 만든다.
- system call 호출 횟수 증가
- 커널 내부 버퍼 관리 오버헤드 증가
- 전체 처리량 감소
이를 해결하는 가장 효과적인 방법은 write 요청을 논리적으로 집계하는 것이다.
헤더, 메시지 타입, 페이로드를 하나의 연속된 버퍼로 구성해 한 번의 write으로 전달하면 동일한 데이터를 훨씬 적은 비용으로 전송할 수 있다.
4. DMA(Direct Memory Access)와 네트워크 I/O의 동작 방식
네트워크 I/O에서 실제 데이터 전송은 CPU가 아니라 NIC(Network Interface Card)가 수행한다.
NIC는 DMA를 통해 CPU 개입 없이 메모리의 데이터를 직접 전송한다.
하지만 중요한 점은 DMA를 설정하기 위해서는 여전히 커널이 개입해야 하며, 이는 system call을 통해서만 가능하다.
즉, DMA는 데이터 복사를 줄여주지만 write 호출 비용 자체를 없애지는 않는다.
5. 현대 시스템에서의 I/O 최적화 방향
현대 시스템에서 I/O 성능의 핵심은 명확하다.
- CPU 계산은 이미 충분히 빠르다
- 병목은 커널 경계, context switching, cache coherence에서 발생한다.
- 따라서 최적화의 초점은 write 호출 횟수 감소에 있다.
이 관점에서 write aggregation, scatter/gather I/O, 비동기 I/O 모델은 모두 같은 문제를 다른 방식으로 해결하는 전략이다.
OutputStream.write() 성능 문제는 멀티쓰레드 여부와 무관하게 system call과 DMA 설정 비용에서 비롯된다.
최적화의 핵심은 "더 빠르게 쓰는 것"이 아니라 "덜 자주 쓰는 것"이다.
Backpressure의 본질과 계층별 구현 전략 : OS부터 Kafka까지
1. Backpressure란 무엇인가
Backpressure는 처리 속도의 불균형을 제어하기 위한 메커니즘이다.
생산자(Producer)가 소비자(Consumer)보다 빠를 때, 소비자가 "더 이상 받을 수 없다"는 신호를 상위로 전달하는 구조를 의미한다.
핵심은 단순한다. "받을 수 있는 만큼만 보내라"
이 원칙이 없다면 시스템은 결국 메모리 고갈, 큐 폭증, 장애 전파로 이어진다.
2. 왜 Backpressure가 없으면 시스템은 붕괴되는가
Backpressure가 없는 시스템은 항상 다음 중 하나로 망가진다.
- 무제한 버퍼 → 메모리 고갈
- 무제한 큐 → 지연(latency) 폭증
- 무제한 요청 →연쇄 실패 (cascading failure)
즉, Backpressure는 성능 최적화가 아니라 시스템 생존을 위한 필수 제어 장치다.
3. OS·네트워크 레벨 Backpressure
가장 낮은 계층의 Backpressure는 이미 OS에 존재한다.
- TCP receive window
- Socket send / receive buffer
- Kernel queue saturation (=포화)
또한 수신 측이 느려지면 :
- window size가 감소하고
- send block 또는 EAGAIN을 반환하며
- 패킷 전송 자체가 지연된다.
이 계층의 특징은 자동으로 처리되고, 투명하지만 제어가 불가능하다.
애플리케이션은 "느려졌다는 사실"만 감지할 뿐, 정책을 직접 설계할 수는 없다.
4. Runtime·Application 레벨 Backpressure
그래서 현대 시스템은 Backpressure를 명시적으로 설계한다.
- Bounded queue
- Demand-based pull 모델
- Credit 기반 흐름 제어
- Reactive stream, request(n)
이 계층의 핵심은 언제 막을지, 얼마나 받을지, 어디서 드롭할지를 개발자가 결정할 수 있다는 점이다.

5. Kafka는 Backpressure를 어떻게 시스템화했는가
Kafka는 Backpressure를 OS에 맡기지 않는다.
Kafka의 접근 방식은 다음과 같다 :
- 파티션 단위 로그 구조
- Consumer pull 모델
- Offset 기반 소비
- fetch size / poll interval 제한
즉, 소비자가 느리면 더 적게 가져가고, 더 늦게 poll하며, 생산자는 로그에만 append한다.
Kafka는 Backpressure를 "큐가 아니라 로그"로 흡수함으로써 시스템 안정성을 확보한다.
이 점에서 Kafka는 단순한 Message Queue가 아니라 Backpressure를 시스템 설계의 중심에 둔 플랫폼이다.
Backpressure는 특정 기술이 아니라 계층을 관통하는 설계 원칙이다.
Kafka는 이를 OS 수준이 아니라, 애플리케이션 아키텍처 수준에서 완성한 대표적인 사례다.
Chunk Size 설계와 GC의 상호작용 : 대용량 시스템에서의 메모리 전략
1. Chunk Size란 무엇이며 왜 중요한가
Chunk Size는 데이터를 어떤 크기로 나누어 메모리에 적재하고 처리할 것인가에 대한 설계 결정이다.
이는 단순한 메모리 사용량 문제가 아니라 GC 동작, CPU 캐시 효율, I/O 전송 방식과 직접적으로 연결된다.
Chunk Size는 크기의 문제가 아니라, 어떤 GC와 어떤 워크로드를 쓰는가의 문제다.
2. 현대 스트리밍 환경에서 KB 단위 Chunk의 한계
YouTube, Netflix 같은 비디오 스트리밍 환경에서 KB 단위 Chunk는 지나치게 작다.
- 너무 많은 객체 생성
- 빈번한 할당과 할당 해제
- GC 주기 증가
- system call 및 I/O 분할 증가
대용량 연속 데이터를 다루는 환경에서 MB 단위 Chunk가 전체 파이프라인 효율을 크게 개선한다.
3. Chunk Size와 Garbage Collection의 균형 문제
Chunk Size는 GC에 직접적인 영향을 미친다.
- 작은 Chunk
- 할당 빈도 증가
- young GC 증가
- 큰 Chunk
- 재할당 비용 증가
- pinning 발생 가능
중요한 점은 Chunk Size는 GC 비용을 없애는 것이 아니라, GC의 형태를 바꾸는 선택이라는 것이다.
4. GC 구현별 Chunk Size 특성 비교
C# Server GC
- Large Object Heap (LOH) 기준: 약 85KB
- 이 이상 객체는 별도 영역으로 취급되며, 압축 비용 증가
- 따라서 85KB는 의도적 경계값
Java ZGC
- region 기반, colored pointer 구조
- 큰 객체는 재할당 빈도가 낮아짐
- 경험적으로 수백 KB 이하는 잦은 이동, 수 MB 이상은 상대적으로 안정적
Azul JDK (Zing / Prime)
- Full GC 없음
- 동시성 압축 (concurrent compaction)
- 객체 이동이 항상 가능함
- Peak throughout 보다 latency 안정성(SLA) 우선
OpenJDK 계열 (HotSpot / Temurin / J9)
- GC 알고리즘에 따르 특성이 크게 다름
- G1 / Shenandoah / Parallel GC 마다 large object 처리 방식 상이
5. Buffer Pooling과 성능 예측의 어려움
Chunk Size가 커질수록 buffer 재사용(pooling)은 필수가 된다.
하지만 여기서 문제가 발생한다.
- VM마다 최적 Chunk Size가 다름
- GC 알고리즘마다 object lifetime 처리 방식이 다름
- 동일 콛라도 JDK / GC / Heap 옵션에 따라 성능 곡선이 달라짐
즉, Chunk Size는 코드로 고정할 수 있는 값이 아닌, 런타임 특성에 종속된 변수다.
Chunk Size는 메모리 크기의 문제가 아니라 GC와 워크로드의 타협 지점이다.
MB 단위 Chunk는 강력한 도구지만, 어떤 VM과 GC를 쓰는지 모른 채 적용하면 독이 될 수 있다.
전송 계층 기반 파일 전송 기능 구현 시 권고 사항
- 대용량 파일 전송 시, 전송이 지연되어 진행도를 파악하기 어려움 → "상태 확인 명령어" 추가 필수
- (OS 간 파일 전송 기능 구현 시) OS 마다 다른 파일 명명 규칙, 사용 불가능한 파일명(=예약어) 고려할 것.
- Magic number 제거
BitTorrent Protocol : 실현될 리 없는 유토피아
현재는 프로그램 업데이트 시에나 많이 사용한다.
애플리케이션 등 현대 기술이 발전하면서 전세계에서 방대한 양의 데이터(BitTorrent의 경우, 조각)이 생성되었다.
이 데이터를 중앙 서버, 중앙 정부 없이 일개 개인이 감당하려고 한다면, 이를 처리하는 개인마다 큰 비용적 부담이 발생하게 된다.
그리고 인간은 본인의 손익에 민감하기 때문에, 남 좋으라고 본인의 손해를 감수하는 일은 절대 없다.
따라서 WEB 3.0은 실현된 적도 없고, 앞으로도 실현될 리 없는 이상적 기술이다.
참고 출처
- (PDF) A Survey on DNS Encryption: Current Development, Malware Misuse, and Inference Techniques
- Apache Kafka — What it is and How it Works. | by Akhilesh Mahajan | Medium
-
Powered By. ChatGPT
'Backend' 카테고리의 다른 글
| [Backend] 9주차 내용 정리 (0) | 2026.01.22 |
|---|---|
| [Backend] Kotlin 기반 HTTP 서버 구현 (0) | 2026.01.16 |
| [Backend] BitTorrent Protocol : 거대 파일을 조각 내어 공유·분산하기 (1) | 2025.12.29 |
| [Backend] TCP 스트림 기반 파일 전송 기능 구현 - CHAT/FILE multiplexing, 단일 Writer, backpressure 구현 기록 (1) | 2025.12.19 |
| [Backend] HTTP 발전의 역사 (1) | 2025.12.08 |