
이 글은 Mozilla의 "Evolution of HTTP" 원문을 번역한 글에 구글링을 통해 찾은 정보를 추가한 게시글입니다.
참고한 블로그들은 하단의 참고 자료에 추가하였으니 세부 정보를 파악하는데 도움이 되었으면 좋겠습니다.
HTTP Protocol의 시작
HTTP (HyperText Transfer Protocol)는 www의 기반 프로토콜이다. 1989년부터 1991년까지 Tim Berners-Lee와 그의 팀이 개발한 HTTP는 유연함을 형성하는 동시에 단순함을 지키는 많은 변화를 거쳤다.
기존의 TCP와 IP 프로토콜을 거쳐 개발된 HTTP는 아래의 4가지 요소로 구성된다.
- HyperText Markup Language (HTML) : Hypertext 문서를 대표하는 본문 양식
- HyperText Transfer Protocol (HTTP) : 이 문서들을 변환하는 프로토콜
- WorldWideWeb (WWW) : 문서들을 표시하는 클라이언트
- httpd 초기 버전 : 문서에 접근하도록 돕는 서버
이 네 가지 요소들은 1990년 말에 완성되었고, CERN(최초의 HTTP)은 1991년 초에 처음으로 실행되었다.
초기의 HTTP 프로토콜은 매우 간단해서 당시에는 '한 줄 프로토콜(one-line protocol)'로 불렸고, 현재는 'HTTP/0.9'로 불린다.
HTTP/0.9 - 한 줄로 구성된 프로토콜
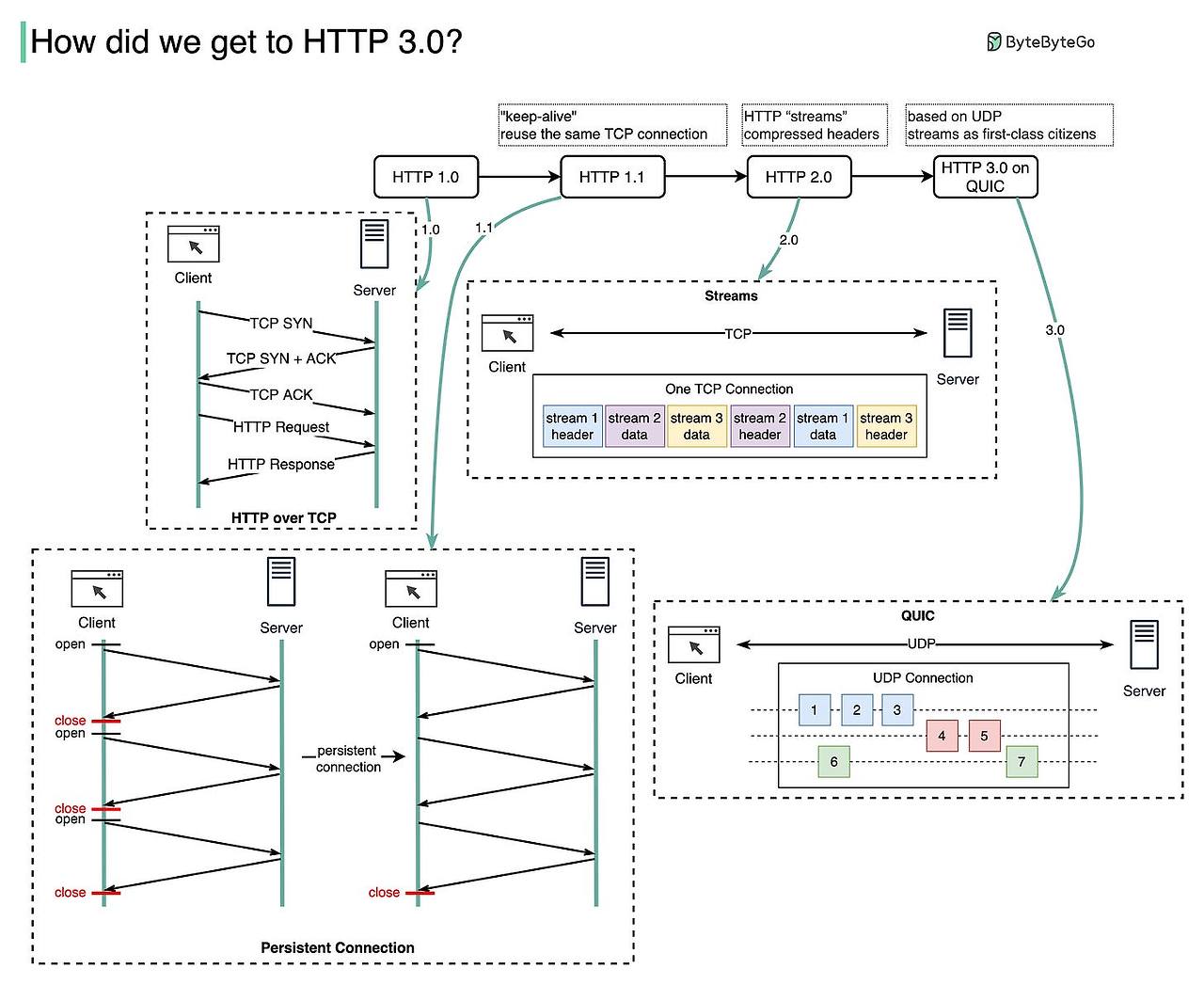
HTTP/0.9는 매우 단순했다. 요청은 한 줄로 작성되었고, GET만이 리소스에 대한 유일한 경로 메서드였다. 서버에 연결되면 프로토콜이나 서버, 포트 번호는 필요하지 않았기 때문에 전체 URL은 포함되지 않았다.
GET /my-page.html
응답도 간단했다. 오로지 파일 내용 자체만 포함되었다.
<html>
A text-only web page
</html>
HTTP headers도 없어서 오직 HTML 파일만 전송할 수 있었다. 상태(status) 혹은 에러(error) 코드도 없었다.
문제가 발생하면 특정 HTML 파일이 생성되었고, 해당 파일 내부에 문제에 대한 설명이 HTML 파일에 추가되었다.
HTTP/1.0 - 웹을 프로토콜로 만들기 시작한 첫 시도
HTTP/0.9는 극도로 단순했다. 요청은 단 한 줄, 응답은 오직 HTML 문서 하나뿐이었다.
하지만 1991년 이후 웹 브라우저와 서버가 빠르게 보급되면서, 이 단순한 모델은 곧 한계에 도달했다.
HTTP/1.0은 웹을 '문서 전송 실험'에서 '범용 애플리케이션 프로토콜'로 확장하기 위한 첫번째 구조화 시도였다.
GET /my-image.gif HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
HTTP/1.0 200 OK
Date: Tue, 15 Nov 1994 08:12:32 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/gif
(image content)1. 버전 정보와 상태 코드의 도입
HTTP/1.0에서 가장 중요한 변화는 요청과 응답이 명확한 형식을 갖게 되었다는 점이다.
# HTTP Request
GET /my-image.gif HTTP/1.0
# HTTP Response
HTTP/1.0 200 OK
요청 라인에 HTTP 버전 정보가 포함되면서 서버는 "이 클라이언트가 어떤 수준의 HTTP를 이해하는지" 알 수 있게 되었다.
응답 역시 상태 코드(Status Code) 형태를 갖게 되면서 아래의 정보를 전송할 수 있게 됐다.
- 브라우저는 성공(2xx), redirection (3xx), 오류(4xx / 5xx)를 구분할 수 있게 됐다.
- 사용자는 더 이상 "페이지가 안 뜬다"가 아니라 " 없는 페이지(404)"라는 개념을 인식하게 되었다.
이 시점부터 클라이언트의 동작이 서버 응답에 따라 분기되기 시작했다.
2. HTTP 헤더의 등장 - 확장성의 핵심
HTTP/1.0의 진짜 핵심은 헤더(Header) 개념의 도입이다.
요청과 응답 양쪽에 헤더가 추가되면서 HTTP는 단순한 텍스트 전송 규칙이 아니라 메타데이터를 자유롭게 확장할 수 있는 프로토콜이 되었다.
# HTTP Request Header
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
# HTTP Response Header
Date: Tue, 15 Nov 1994 08:12:32 GMT
Server: CERN/3.0 libwww/2.17
구체적으로 아래와 같은 메타데이터 정보들을 제공할 수 있게 되었다.
- 브라우저 종류 식별 (User-Agent)
- 서버 구현 정보 전달
- 날짜, 캐싱, 인증, 인코딩 등
HTTP가 "극도로 유연하고 확장성이 높다"는 평가는 바로 이 헤더 구조 덕분이다.
3. Content-Type 헤더 - 웹이 HTML을 벗어나다
HTTP/0.9에서는 응답이 무엇인지 알 방법이 없어, 모든 것은 "HTML일 것"이라는 암묵적 가정 위에 있었다.
HTTP/1.0에서 Content-Type 헤더가 등장하면서 상황이 변했다.
Content-Type: text/gif
(image content)
이를 통해 서버는 이미지, 텍스트, 이진 데이터를 명시적으로 구분해 전송할 수 있게 되었고, 브라우저(클라이언트)는 이를 해석하는 주체가 되었다.
이 순간부터 웹은 문서가 아니라 멀티미디어 애플리케이션 플랫폼으로 확장되기 시작했다.
당시의 현실 : 표준이 아니라 관행의 집합
중요한 점은 HTTP/1.0은 처음부터 잘 정리된 표준이 아니었다는 것이다.
1991년부터 1995년 동안 서버는 구현체마다 동작이 달랐고, 브라우저마다 지원 헤더도 달랐으며, 같은 요청이라도 결과가 달라지는 일이 흔했다.
즉, 상호 운용성(interoperability) 문제가 일상적이었다.
이 혼란을 정리하기 위해 1996년에 HTTP/1.0을 설명하는 정보성 문서인 RFC 1945가 게시된다.
RFC 1945는 이미 현장에서 사용되고 있던 관행을 정리한 문서에 가깝다.
그래서 HTTP/1.0은 실험과 진화의 산물이고, 깔끔한 설계보다는 빠른 확장이 우선된 결과이며, 동시에 다음 버전(HTTP/1.1)의 문제 목록을 만든 버전이기도 하다.
HTTP/1.1 - 표준화된 프로토콜, 그리고 성능 문제의 시작
HTTP/1.0이 현장의 요구에 의해 자연스럽게 확장된 결과였다면,
HTTP/1.1은 처음으로 명시적 표준을 목표로 설계된 HTTP 버전이다.
HTTP/1.0이 등장한 직후부터 브라우저와 서버 구현체는 빠르게 진화했지만,
서로 다른 해석과 구현 차이로 인해 상호 운용성 문제는 점점 심각해졌다.
이를 정리하기 위해 1997년 초, HTTP/1.1이 등장했다.
HTTP/1.1의 목표는 분명했다.
모호함을 제거하고, 실제 웹 트래픽을 감당할 수 있는 프로토콜을 만들자.
GET /en-US/docs/ HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:141.0) Gecko/20100101 Firefox/141.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br, zstd
Connection: keep-alive
HTTP/1.1 200 OK
accept-ranges: none
content-encoding: br
date: Tue, 01 Jul 2025 08:32:50 GMT
expires: Tue, 01 Jul 2025 09:26:50 GMT
cache-control: public, max-age=3600
age: 1926
last-modified: Sat, 28 Jun 2025 00:47:12 GMT
etag: W/"b55394ed2f274eea5d528cf6c91e1dcf"
content-type: text/html
vary: Accept-Encoding
content-length: 26178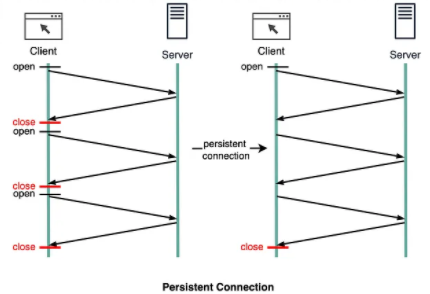
1. 연결 재사용 (Persistent Connection)
HTTP/1.1에서 가장 큰 변화는 연결 재사용(keep-alive)이 기본 동작이 되었다는 점이다.
HTTP/1.0에서는 리소스 하나를 받을 때마다 TCP 연결을 새로 열고 닫았다. HTML 문서 하나에 이미지, CSS, JavaScript가 포함되면 브라우저는 같은 서버에 대해 여러 TCP 연결을 반복적으로 생성해야 했다.
HTTP/1.1에서는 하나의 TCP 연결을 열고, 그 연결 위에서 여러 요청과 응답을 순차적으로 처리했다.
이로 인해 TCP 3-way handshake 비용이 감소했고, TLS 사용 시에도 handshake 비용이 대폭 절감됐다.
무엇보다 TCP slow start를 다시 겪지 않아도 된다는 이점으로 웹 체감 속도가 크게 개선되었다.
TLS slow start와 장기 연결의 의미
TCP 연결은 생성 직후에는 전송 속도가 제한된다. (slow start)
연결이 오래 유지될 수록 혼잡 윈도우가 커지고, 더 빠른 전송이 가능해진다.
즉, 오래 살아남은 TCP 연결이, 새로 만든 연결보다 빠르다.
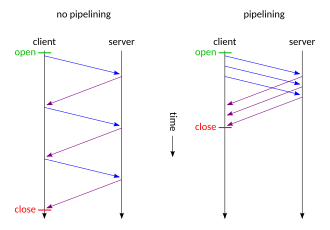
2. Pipelining - 이상적인 해법, 현실에서는 실패
HTTP/1.1은 HTTP pipelining이라는 기능도 도입했었다.
첫 번째 요청의 응답이 오기 전에 두 번째, 세 번째 요청을 연속으로 전송 가능하도록 돕는 것으로,
이론적으로는 RTT(latency)를 크게 줄일 수 있는 기능이었다.
그러나 현실은 달랐다.
- 서버 구현체마다 pipelining 처리 품질이 달랐고
- 하나의 응답이 지연되면 뒤의 모든 응답이 막히는 Head-of-Line(HOL) Blocking 문제가 발생했으며
- proxy / load balancer 등 중간 장비와의 호환성 문제도 존재했다.
결과적으로, pipelinining은 스펙에는 존재했지만, 대부분의 브라우저에서는 비활성화되었다.
이 실패는 이후 HTTP/2 설계에 직접적인 영향을 줬다.
3. Host 헤더 - 가상 호스팅의 출발점
HTTP/1.1에서 Host 헤더는 필수가 되었다.
Host: developer.mozilla.org
이 한 줄로 서버 운영 방식이 획기적으로 바뀌었다.
IP 주소 하나와 TCP 포트 하나로 여러 도메인 호스팅이 가능해진 것이다.
HTTP/1.0 시절에는 도메인 하나 당 IP 하나가 필요했다.
HTTP/1.1 이후로 가상 호스팅(collocation)이 가능해졌고, 웹 호스팅 산업이 본격적으로 확장되었다.
4. Chunked Transfer Encoding - 실시간 전송의 출발점
보통 HTTP 응답은 전체 길이를 미리 알려주는 Content-Length 헤더를 포함한다.
하지만 데이터가 너무 크거나, 서버에서 실시간으로 생성 중이라 전체 크기를 미리 알 수 없는 경우가 많다.
그래서 HTTP/1.1은 Transfer-Encoding : chunked를 도입하여 데이터를 조각(chunk) 단위로 전송 가능해졌다.
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: text/plain
4\r\n <-- 첫 번째 조각의 크기 (16진수, 4바이트)
Wiki\r\n <-- 실제 데이터
5\r\n <-- 두 번째 조각의 크기 (5바이트)
pedia\r\n <-- 실제 데이터
0\r\n <-- "이제 끝났다"는 신호 (크기 0)
\r\n
전체 데이터가 준비될 때까지 기다릴 필요 없이, 준비된 부분부터 즉시 브라우저에 전송할 수 있게 되어 사용자 체감 속도가 크게 개선되었다. 이는 서버에서 동적으로 생성되는 컨텐츠, 스트리밍 성격의 응답, 프록시를 거치는 환경에서 필수였다.
이 기능은 이후 스트리밍 API, SSE (Server-Sent Events), 프록시 캐시의 기반이 되었다.
5. Content Negotiation & Cache Control - 지능적인 통신
이 기술은 서버가 클라이언트의 상황(기기 언어, 지원 압축 방식, 화면 크기 등)에 맞춰 최적의 결과물을 골라주는 과정이다.
Content Negotiation
- Accept-Langue : en-US,en;q=0.5
- Vary 헤더 : 서버가 응답할 때 Vary: Accept-Language라고 보내면, "이 응답은 언어 설정에 따라 달라질 수 있으니 캐시할 때 주의하라"는 뜻이다.
Cache Control
데이터를 매번 새로 받지 않고 재사용하는 규칙이다.
- ETag (Fingerprint) : 파일의 내용이 바뀌었는지 확인하는 고유 식별자
- 클라이언트 : If-None-Match 태그로 파일 유효성 여부 검사
- 서버 : 304 Not Modified 응답으로 여전히 유효함을 응답(=증명)
이로 인해 브라우저, 모바일, 프록시, CDN이 협력하는 구조가 만들어지면서 "같은 URL, 다른 응답" 개념이 정착되었다.
HTTP/1.1의 근본적 한계
HTTP/1.1은 많은 문제를 해결했지만, 동시에 치명적인 구조적 한계를 고정시켰다.
- 하나의 TCP 연결 위에서 요청/응답은 본질적으로 순차적
- 응답 하나가 느리면 뒤의 요청이 모두 대기
- 리소스가 많아질 수록 성능 저하
이 문제를 완화하기 위해 브라우저는 결국 도메인 당 여러 TCP 연결을 강제로 생성했고,
connection pool / sharding / sprite image 같은 편법을 사용하게 되었다.
HTTP/1.1은 표준화에는 성공했지만, 성능 문제는 근본적으로 해결하지 못했다.
HTTP/2 - 더 나은 성능, 구조의 전환
HTTP/1.1이 표준화에는 성공했지만, 웹 페이지가 점점 복잡해지면서 그 한계는 빠르게 드러났다.
이미지, CSS, JavaScript는 기본이 되었고, 일부 웹 페이지는 더 이상 문서가 아니라 애플리케이션에 가까워졌다.
요청 수는 폭발적으로 증가했고, HTTP/1.1의 연결 재사용 모델은 점점 더 많은 부담을 떠안게 되었다.
문제는 명확했다.
하나의 TCP 연결 위에서 요청과 응답을 순차적으로 처리하는 구조가 현대 웹의 트래픽 패턴을 감당하지 못한다.
SPDY - HTTP/2의 실험실
이 문제를 가장 먼저 정면으로 다룬 것이 Google이었다.
2010년대 초반, Google은 SPDY라는 실험적 프로토콜을 공개했다.
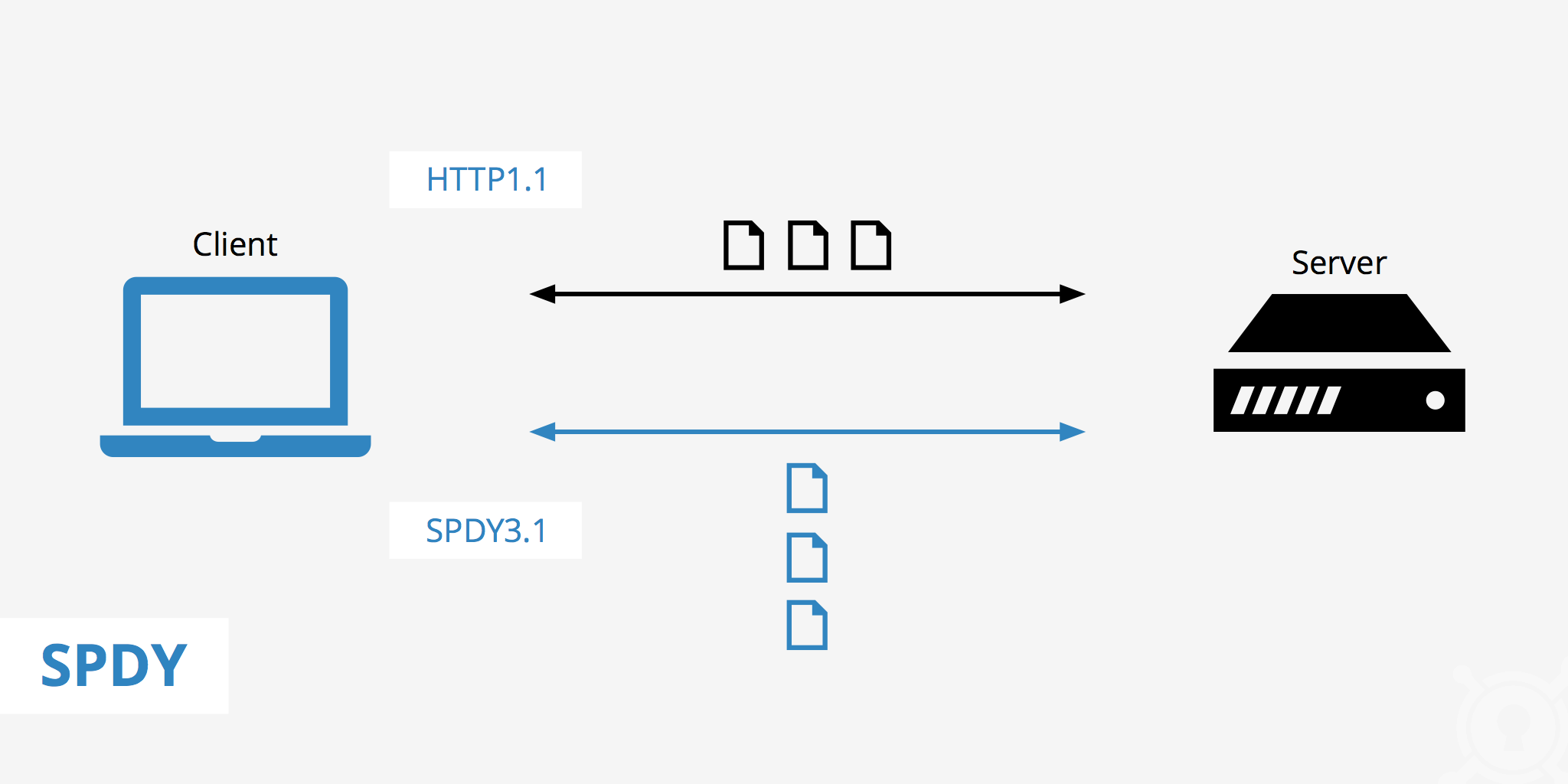
SPDY의 목표는 단순했다 :
- 더 빠른 페이지 로딩
- RTT 감소
- 중복 데이터 전송 제거
- 연결 수 감소
SPDY는 실제로 단일 TCP 연결 위에서 여러 요청을 병렬로 처리했고, 헤더 압축을 통해 불필요한 오버헤드를 줄이며 브라우저와 서버 양쪽에서 즉각적인 성능 개선을 보여주었다.
이 실험의 성공이 HTTP/2의 출발점이었다.
1. 텍스트가 아닌 이진(binary) 프로토콜
HTTP/1.x는 사람이 읽을 수 있는 텍스트 기반이었다. 디버깅에는 편리했지만, 성능 최적화에는 불리했다.
HTTP/2는 모든 통신을 이진 프레임(binary frame)으로 정의한다.
- 파싱(Parsing) 비용 감소
- 명확한 프레임 경계
- 중간 장비의 오작동 감소
즉, HTTP는 더 이상 "사람이 읽는 프로토콜"이 아니라 기계 간 고성능 통신 프로토콜로 전환되었다.
2. Multiplexing - HTTP/1.1의 근본적 한계 해결
HTTP/2의 가장 중요한 변화는 멀티플렉싱(단일 TCP 연결 위에서 여러 요청과 응답을 동시에 병렬 처리)이다.
HTTP/1.1에서는 하나의 응답이 느리면 뒤의 요청들이 대기했다.
이를 회피하기 위해 다중 TCP 연결을 생성하기도 했지만 결국 네트워크와 서버에 부하가 증가하게 되었다.
HTTP/2는 요청과 응답이 스트림(stream)으로 분리되어 서로 독립적으로 전송된다.

3. 헤더 압축 (HPACK)
HTTP 요청과 응답에서 Cookie, User-Agent, Accept 계열 같은 헤더가 반복되는 경우는 매우 많다.
HTTP/2는 HPACK 헤더 압축 방식을 도입하여 중복 헤더를 테이블로 관리하며 변경된 부분만 전송하게 되었다.
그 결과, 네트워크 대역폭이 절약되었고, 이는 모바일 환경에서 특히 큰 효과를 보았다.
4. Server Push - 이론과 현실의 간극
HTTP/2는 서버가 클라이언트 요청 없이도 리소스를 미리 전송할 수 있는 Server Push를 도입했다.
이론적으로는 브라우저가 HTML 요청 시, 서버가 CSS/JS를 함께 보내 RTT(왕복 시간)를 단축하여 속도를 향상시키는 것이 목적이었다.
하지만 현실에서는 서버가 브라우저의 캐시 상태를 몰라, 이미 있는 파일을 또 보내는 캐시 중복 문제, 초기 HTML 전송 대역폭을 Push 리소스가 점유하여 오히려 첫 화면 렌더링 지연 문제, 무엇보다 중요한 HTML 문서가 먼저 전송되어야 하는데 덩치 큰 JS 파일이 Push 되는 우선순위 역전 현상이 발생했다.
결국, 웹 브라우저의 절대 강자인 크롬(Chromium)이 2022년부터 HTTP/2 Server Push 지원을 공식적으로 제거한 것을 시작으로, "복잡성에 비해 성능적 이득이 거의 없는 기술"로 취급되었다.
HTTP/2의 도입과 확산, 그리고 한계
HTTP/2는 2015년 5월에 공식 표준(RFC 7540)으로 발표되었다.
- 기존 HTTP API와 호환
- 애플리케이션 코드 변경 불필요
- 브라우저와 서버만 지원하면 자동 적용
이 덕분에 HTTP/2는 빠르게 확산되었고, 2022년 1월에 모든 웹사이트 중 46.9%로 정점을 찍었다.
(2025년 12월 현재는 35% 근처를 유지 중이다.)

그러나 HTTP/2 역시 완전한 해답은 아니었다.
HTTP/2는 HTTP/1.1의 애플리케이션 레벨 병목을 해결했지만, TCP 위에서 동작하는 한계는 그대로 남아 있었다.
- TCP 레벨 Head-of-Line Blocking
- 패킷 하나 손실 시, 해당 연결의 모든 스트림 영향
- 모바일/불안정 네트워크 환경에서 성능 저하
이 문제는 결국 HTTP/3(QUIC)로 이어졌다.
HTTP 3 - QUIC을 통한 HTTP, 전송 계층을 바꾸다
HTTP/3는 "HTTP의 다음 버전"이지만, 실질적으로는 전송 계층 전략의 전환이었다.
HTTP/1.1과 HTTP/2가 모두 TCP 위에서 동작했다면, HTTP/3는 TCP를 완전히 벗어나 QUIC(UDP 기반 전송 프로토콜) 위에서 실행된다.
이 선택은 단순한 성능 개선이 아니라, HTTP/2에서 더 이상 해결할 수 없었던 문제를 근본적으로 제거하기 위한 결정이었다.
HTTP/2의 마지막 한계 : TCP Head-of-Line Blocking
HTTP/2는 애플리케이션 레벨에서 멀티플렉싱을 구현했다.
- 하나의 TCP 연결
- 여러 개의 HTTP 스트림
- 프레임 단위 병렬 전송
하지만 여기에는 치명적인 한계가 있었다.
TCP는 연결 단위로 신뢰성을 보장한다.
즉, TCP 패킷 하나가 손실되면 해당 연결 위의 모든 HTTP/2 스트림이 재전송을 기다리며 정지해야만 했다.
HTTP/2는 HTTP/1.1의 성능 문제를 해결했지만, TCP 자체의 근본적 특성까지 바꾸지는 못했다.
QUIC - TCP를 사용자 공간에서 다시 설계하다
QUIC은 Google이 처음 설계하고, 이후 IETF 표준으로 정제된 UDP 기반 전송 프로토콜이다.
핵심은 단순하다.
TCP가 제공하던 기능을 UDP 위에서, 애플리케이션 계층에서 직접 구현한다.
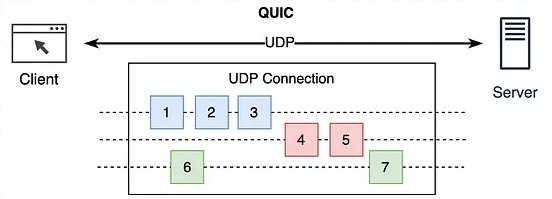
1. 스트림 단위 독립 전송 - 진짜 멀티플렉싱
QUIC은 하나의 연결 안에 여러 개의 독립 스트림을 가진다.
중요한 차이점은 이거다.
- 스트림 A에서 패킷 손실이 발생해도
- 스트림 B,C는 영향 없이 계속 진행
즉, HOL Blocking이 연결 단위가 아니라 스트림 단위로 격리된다.
2. 낮은 지연 시간 - Handshake 감소
QUIC은 기본적으로 TLS 1.3을 통합한다.
- TCP + TLS → 최소 2~3 RTT 필요
- QUIC → 1 RTT, 경우에 따라 0 RTT
모바일 환경이나 지연이 잦은 네트워크에서 체감 성능 차이가 매우 크다.
3. 연결 이동성 (Connection Migration)
TCP 연결은 IP / 포트 변경 시 끊어진다.
반면, QUIC 연결은 연결 식별자를 사용하여 IP 변경에도 연결 유지가 가능하다.
현대의 Wi-Fi ↔ LTE 전환, 네트워크 변경 같은 상황에서도 연결을 다시 맺지 않는다.
모바일 웹과 스트리밍 서비스에 결정적인 장점이다.
HTTP/3의 정의와 지원 현황
HTTP/3는 RFC 9114로 정의되어, 현재는 Chromium 기반 브라우저 (Chrome, Edge), Firefox, 주요 CDN 및 웹 서버에서 모두 지원된다.
2022년 10월까지 모든 웹사이트의 26%가 HTTP/3를 사용하고 있었다. (2025년 12월 현재는 35%를 상회하고 있다.)
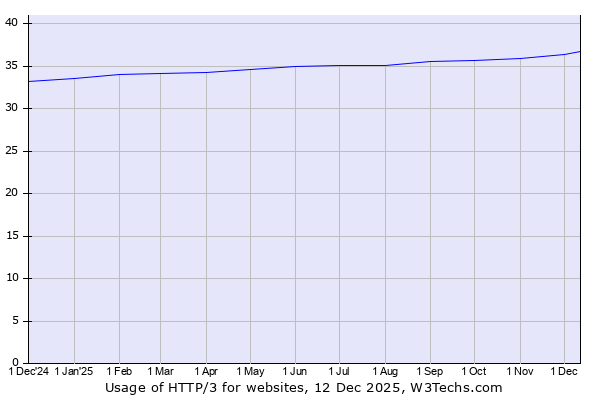
하지만 HTTP/3가 "무조건 더 좋다"는 의미가 아니다
실무 관점에서 HTTP/3는 장단점이 분명하다.
장점
- TCP HOL 완전 제거
- 모바일 환경에서 압도적 성능
- 연결 재사용 및 이동성
단점
- UDP 차단 환경에서는 동작 불가
- 방화벽 / NAT / 보안 장비와의 호환성 이슈
- 서버 구현 복잡도 증가
- 디버깅 난이도 상승
그래서 현재도 대부분의 서비스는 HTTP/1.1, HTTP/2, HTTP3를 동시에 지원하고, 상황에 따라 협상한다.
HTTP 버전별 핵심 차이 요약
| 구분 | HTTP/1.x | HTTP/2 | HTTP/3 |
| 전송 계층 | TCP | TCP | QUIC (UDP 기반) |
| 메시지 형식 | 텍스트 | 이진 (Binary) | 이진 (Binary) |
| 요청 처리 방식 | 순차 처리 | 멀티플렉싱 | 멀티플렉싱 |
| 연결 단위 | 요청 마다 또는 keep-alive | 단일 TCP 연결 | 단일 QUIC 연결 |
| HOL Blocking | 애플리케이션 + TCP | TCP 레벨 HOL 존재 | 스트림 단위로 완전 제거 |
| 병렬성 | 브라우저 레벨 우회 필요 | 논리적 병렬 | 실제 병렬 (스트림 독립) |
| 헤더 처리 | 중복 전송 | HPACK 압축 | QPACK 압축 |
| 패킷 손실 영향 | 연결 전체 | 연결 전체 | 해당 스트림만 영향 |
| 모바일 환경 | 취약 | 개선됨 | 매우 강함 (Connection Migration) |
| 실무 난이도 | 낮음 | 중간 | 높음 |
결론 : HTTP 버전의 진화는 "전송을 다루는 방식"의 변화다
HTTP의 버전 변화는 단순한 기능 추가가 아니라, 웹이 성장하면서 드러난 성능 병목을 점점 더 낮은 계층에서 해결해 온 과정이다.
HTTP/1.0과 1.1은 상태 코드, 헤더, 연결 재사용을 통해 웹의 기본 구조를 확립했지만 요청-응답의 직렬적 한계를 가졌다.
HTTP/2는 이진 프로토콜과 멀티플렉싱으로 연결 효율과 병렬성을 크게 개선했으나 TCP 기반의 제약이 여전히 남아 있었다.
HTTP/3는 QUIC(UDP 기반)을 채택해 스트림 단위 손실 복구와 낮은 지연을 가능하게 하며, 전송 계층 수준에서 성능 문제를 해결한 첫 HTTP 버전이다.
즉, HTTP의 진화는 애플리케이션이 아닌 전송 방식 자체를 재설계해 온 역사다.
참고 자료
- http2 - HTTP/2 HEADERS and DATA Frames - Stack Overflow
- HTTP 1.0 -> HTTP 1.1 -> HTTP 2.0 -> HTTP 3.0 (QUIC)
Powered By. ChatGPT
'Backend' 카테고리의 다른 글
| [Backend] BitTorrent Protocol : 거대 파일을 조각 내어 공유·분산하기 (1) | 2025.12.29 |
|---|---|
| [Backend] TCP 스트림 기반 파일 전송 기능 구현 - CHAT/FILE multiplexing, 단일 Writer, backpressure 구현 기록 (1) | 2025.12.19 |
| [Backend] JVM - Primitive type과 Reference type (1) | 2025.12.02 |
| [Backend] ShadowJar 플러그인 적용 후 “기본 Manifest 속성이 없습니다” 오류 해결기 (0) | 2025.11.24 |
| [Backend] Kotlin tips (0) | 2025.11.24 |